Python 크롤링 - Scrapy Tutorial
네이버 뉴스를 스크래핑해보자!
- 새로운 Scrapy 프로젝트를 생성한다.
scrapy startproject tutorial
- setting.py 에서
ROBOTSTXT_OBEY = False로 변경한다.
- 추출할 아이템을 정의한다.
spiders폴더 안에 naver_spider.py를 생성한다.
import scrapy
class NaverSpider(scrapy.Spider):
name = "naver"
def start_requests(self):
urls = ['https://news.naver.com/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=003&aid=0010035514&date=20200823&type=1&rankingSeq=6&rankingSectionId=102']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
content = response.xpath('//*[@id="main_content"]').getall()
self.log(content)
name : Spider를 식별하는 고유한 이름
start_requests() : Spider가 크롤링을 최초로 시작하는 메서드. 반드시 반복가능한 Requests를 반환해야함
parse() : 각 요청에 대해 다운로드 된 응답을 처리하기 위해 호출되는 메서드
- naver_spider.py를 실행해보자
scrapy crawl naver
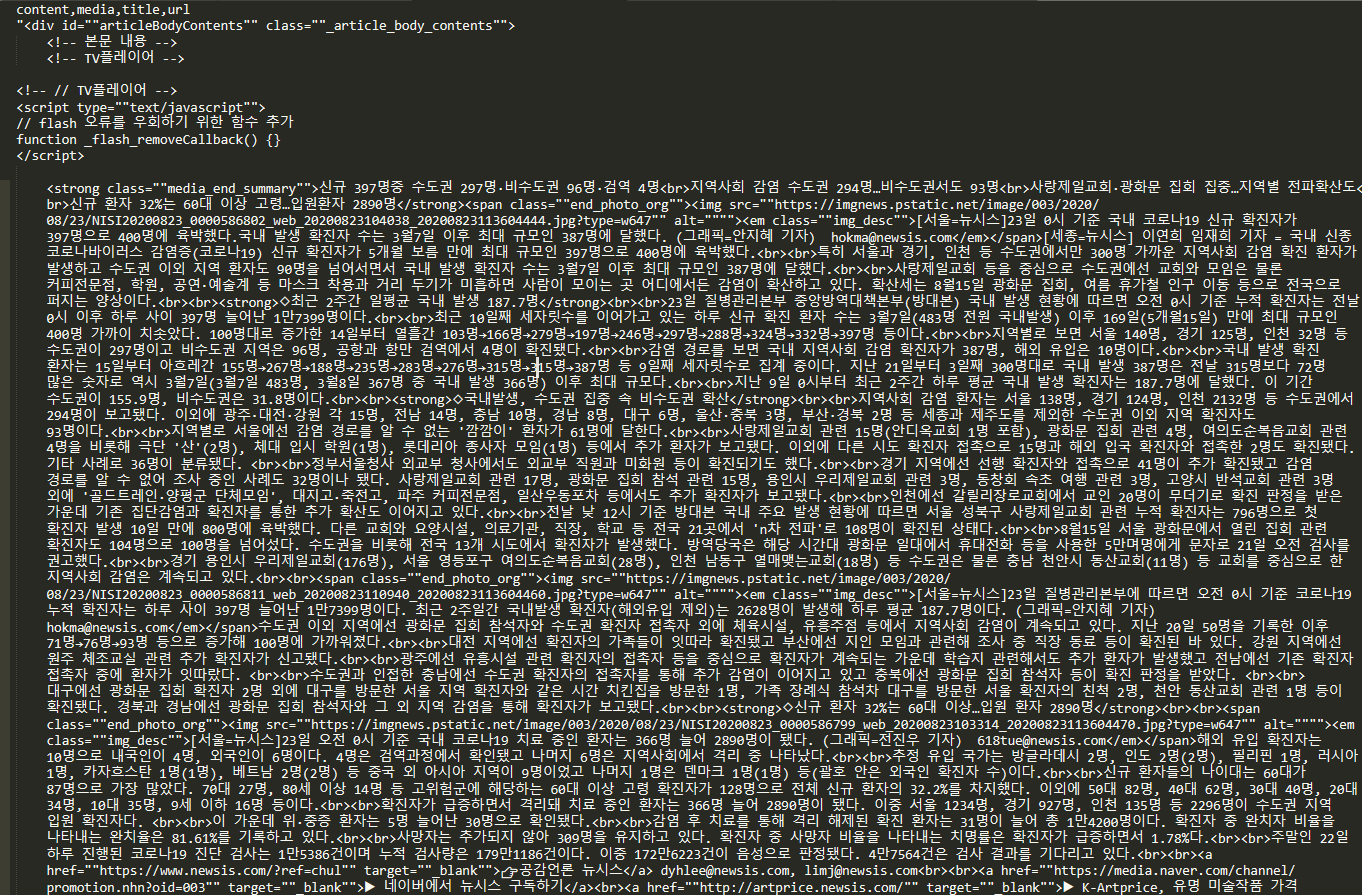
아래의 사진과 같이 결과가 출력된다.
모든 데이터를 가져왔다면 이제, 필요한 데이터만 수집해보자
- 필요한 데이터를 정의내린다.
1) 아래와 같이 라인을 활성화한다. ( in settings.py)
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 300,
}
2) 나의 item을 정의한다. ( in items.py)
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
url = scrapy.Field() # url
title = scrapy.Field() # 기사 제목
media = scrapy.Field() # 기사 미디어
content = scrapy.Field() # 기사 본문
3) items.py에서 정의한 item을 설정한다. (in naver_spider.py)
import scrapy
from tutorial.items import TutorialItem
class NaverSpider(scrapy.Spider):
name = "naver"
def start_requests(self):
urls = ['https://news.naver.com/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=003&aid=0010035514&date=20200823&type=1&rankingSeq=6&rankingSectionId=102']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
item = TutorialItem()
item['url'] = response.url
item['title'] = response.xpath('//*[@id="articleTitle"]').get()
item['media'] = response.xpath('//*[@id="main_content"]/div[1]/div[1]/a/img').get()
item['content'] = response.xpath('//*[@id="articleBodyContents"]').getall()
yield item
4) 리턴받은 item을 csv로 저장하자 (in pipelines.py)
from itemadapter import ItemAdapter
from scrapy.exporters import CsvItemExporter
class TutorialPipeline:
def process_item(self, item, spider):
with open('news.csv', 'wb') as f:
exporter = CsvItemExporter(f, encoding='utf-8')
exporter.export_item(item)
return item
5) 저장한 csv을 열어보자
code news.csv