Python 크롤링 - Scrapy(스크래피)란?
Scrapy란?
python으로 작성된 웹 크롤링 프레임 워크로 “spiders”를 작성해서 크롤링을 한다.
https://docs.scrapy.org/en/latest/index.html
Data flow
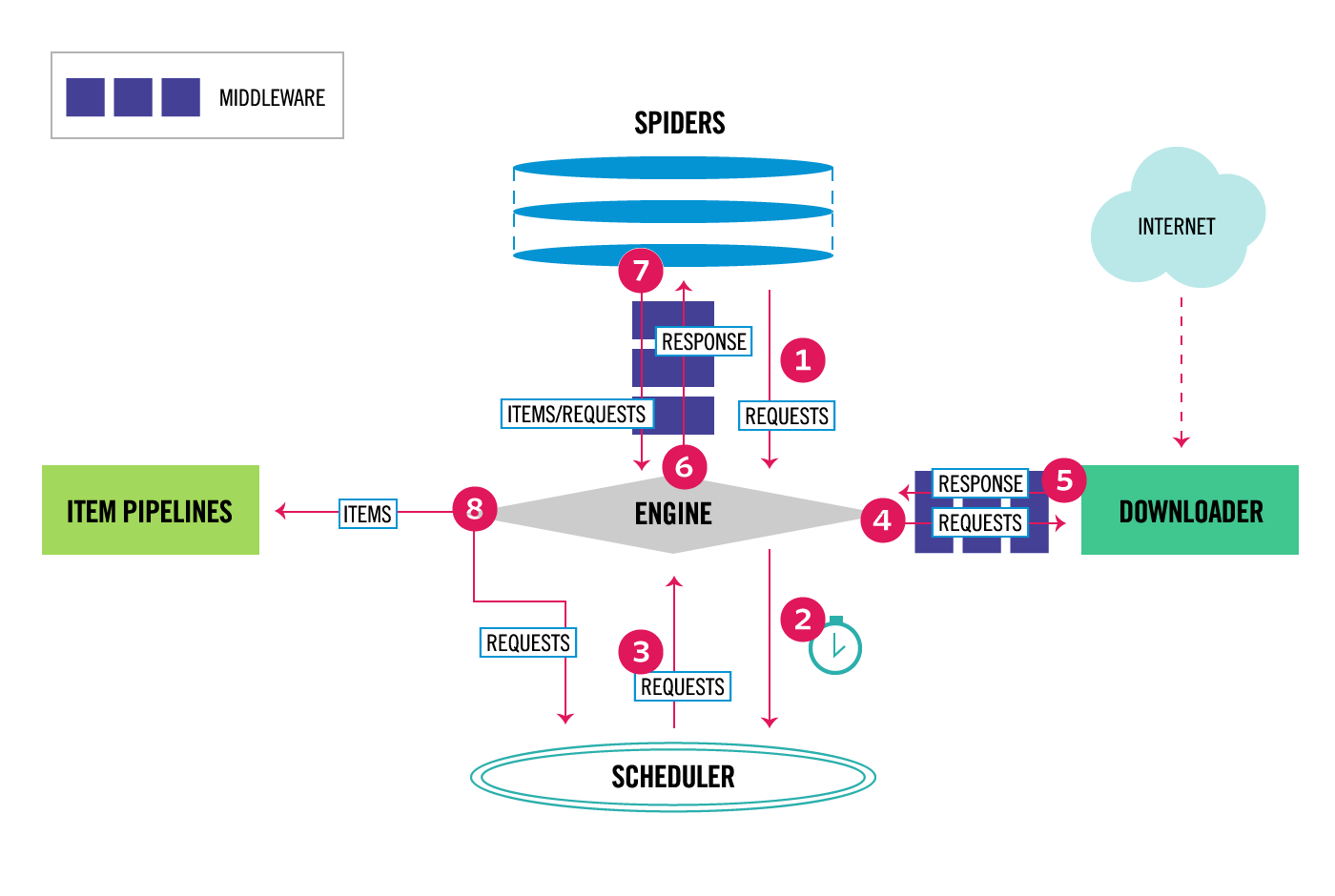
Engine은Spider로부터 초기 Requests를 받는다.Engine은 Requests를Scheduler에 의해 스케줄링 된다.Scheduler는Engine에게 다음 Requests를 반환한다.Engine은Downloader에게 Requests를 보내면Middleware를 통해 이동하게된다.- Requests에 의해 받아온 데이터들을 다시
Middleware를 통해 Engine로 전송된다. Engine은Downloader에게 받은 Response를 받고, 이를Spider Middleware를 통해 Spider에게 보낸다. (작성된 비즈니스 로직이 적용됨)Spider는 Response를 처리하고 새로운 Requests를Spider Middleware를 통해Engine에 반환한다.Engine은Item Pipelines로 처리된 데이터를 보낸다음 처리된 Requests를Scheduler에 보낸다.- step1~8의 과정을
Scheduler로부터 추가의 요청이 없을때까지 반복한다.
Engine : 시스템의 모든 구성요소간의 데이터 흐름을 제어하고 특정 작업이 발생할때 이벤트 트리거의 역할을 한다.
Scheduler : 엔진에서 요청을 수신하고 엔진이 요청하면 나중에 엔진에서 요청할 때 공급하기 위해 대기열에 추가한다.
Downloader : 웹 페이지를 가져와서 엔진에 공급하는 역할을 한다.
Spiders : 사용자가 작성한 클래스
Item Pipeline : 스파이더에 의해 아이템이 추출되면 아이템 처리를 담당한다.
Scrapy 설치
# pip를 사용해 다운
pip install scrapy
Scrapy 프로젝트 시작
원하는 위치로 이동 후 아래와 같은 명령어를 작성하면 scrapy 프로젝트가 세팅된다.
scrapy startproject tutorial
그러면 아래와 같은 디렉토리가 생성된다.
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
- item.py : 크롤링할 데이터를 저장하는 기능을 하는 객체의 클래스를 정의하는 파일이다.
- middlewares.py : 커스텀한 middleware의 기능을 정의하는 파일이다.
- pipelines.py : item pipelines의 커스텀 모듈을 정의하는 곳으로 데이터를 가공하고 저장하는 역할을 한다.
- settings.py : 현재 프로젝트의 설정을 하는 파일이다.