파이썬 알고리즘 인터뷰_파이썬 문법
- 파이썬 알고리즘 인터뷰 서적 내용을 정리
파이썬 자료형
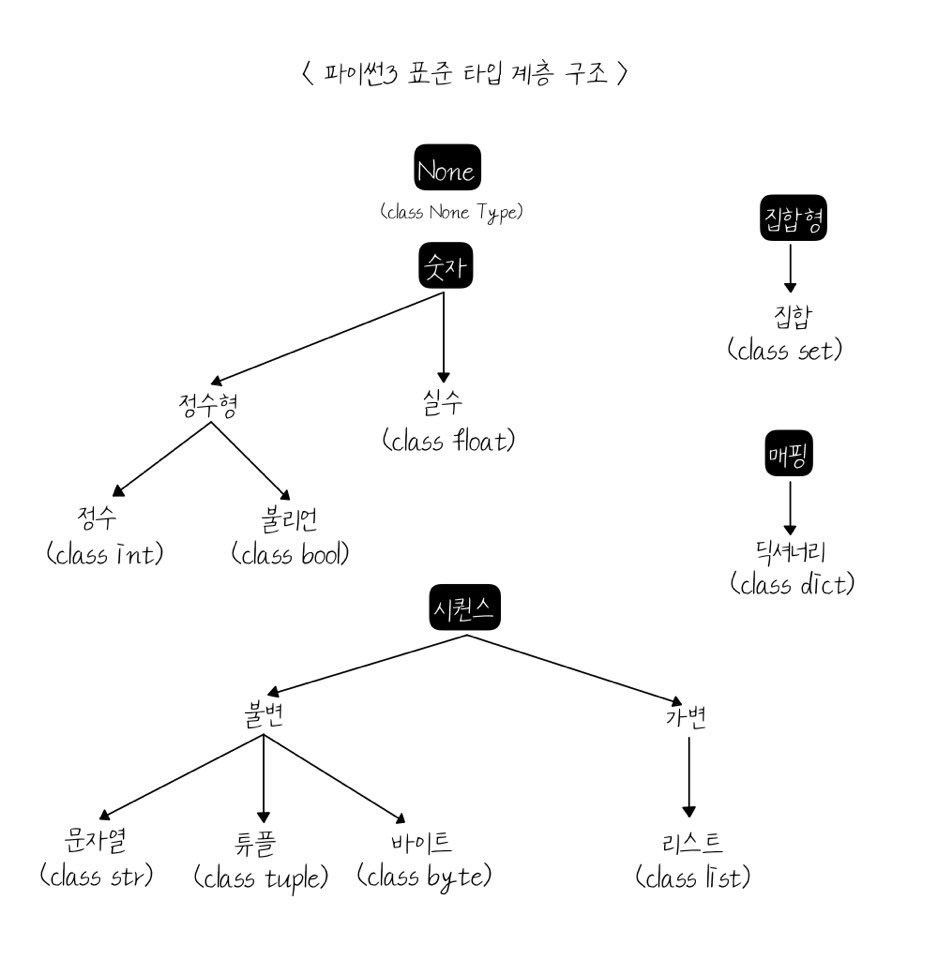
리스트(List)
순서대로 저장하는 시퀀스이자 변경 가능한 목록을 의미한다. 입력 순서가 유지되며, 내부적으로 동적 배열로 구현되어있다.
리스트는 다양한 기능을 제공한다. 리스트 마지막에 요소를 .append()로 추가하거나, 리스트 마지막 요소를 pop()로 추출하거나, 원하는 인덱스의 요소를 조회하는 연산은 모드 O(1)이다.
반면, 요소를 삭제하거나 큐의 연산이기도 한 첫 번째 요소를 추출하는 pop(0)은 O(n)이므로 리스트에서 큐의 연산을 사용할 때는 주의해야 한다.
| 연산 | 시간 복잡도 | 설명 |
|---|---|---|
| len(a) | O(1) | 전체 요소의 개수를 리턴한다. |
| a[i] | O(1) | 인덱스 i의 요소를 가져온다. |
| a[i:j] | O(k) | i부터 j까지 슬라이스의 길이만큼 k개의 요소를 가져온다. 이 경우 객체 k개에 대한 조회가 필요하므로 O(k)이다. |
| elem in a | O(n) | elem 요소가 존재하는지 확인한다. 처음부터 순차 탐색하므로 n만큼 시간이 소요된다. |
| a.count(elem) | O(n) | elem 요소의 개수를 리턴한다. |
| a.index(elem) | O(n) | elem 요소의 인덱스를 리턴한다. |
| a.append(elem) | O(1) | 리스트 마지막에 elem 요소를 추가한다. |
| a.pop() | O(1) | 리스트 마지막 요소를 추출한다. 스택의 연산이다. |
| a.pop(0) | O(n) | 리스트 첫번째 요소를 추출한다. 큐의 연산이다. 이 경우 전체 복사가 필요하므로 O(n)이다. 큐의 연산을 주로 사용한다면 리스트보다 O(1)에 가능한 데크(deque)를 권장한다. |
| del a[i] | O(n) | i에 따라 다르다. 최악의 경우 O(n)이다. |
| a.sort() | O(nlogn) | 정렬한다. 팀소트를 사용하며 최선의 경우 O(n)에도 실행될 수 있다. |
| min(a), max(a) | O(n) | 최솟값/최댓값을 계산하기 위해서는 전체 선형 탐색해야 한다. |
| a.reverse() | O(n) | 뒤집는다. 리스트는 입력 순서가 유지되므로 뒤집게 되면 입력 순서가 반대로 된다. |
| a.insert(elem) | O(n) | 특정 위치의 인덱스를 지정해 요소를 추가한다. |
딕셔너리(dict)
키/값 구조로 이뤄진 딕셔너리를 의미한다. 입력 순서가 유지되며(python 3.7+), 내부젇으로는 해시 테이블로 구현되어있다.
해시 테이블은 다양한 타입을 키로 지원하며 입력과 조회의 시간복잡도는 O(1)이다. 최악의 경우에는 O(n)이 될 수 있다.
| 연산 | 시간 복잡도 | 설명 |
|---|---|---|
| len(a) | O(1) | 요소의 개수를 리턴한다. |
| a[key] | O(1) | 키를 조회하여 값을 리턴한다. |
| a[key] = value | O(1) | 키/값을 삽입한다. |
| key in a | O(1) | 딕셔너리에 키가 존재하는지 확인한다. |
| del a[‘key’] | O(1) | 딕셔너리 요소 삭제 |
파이썬 딕셔너리를 효율적으로 생성하기 위한 추가 모듈을 지원한다.
파이썬 3.6 이하에서 항상 입력 순서가 유지되는 collections.OrderedDict()를 비롯해, 조회 시 항상 디폴트 값을 생성해 키 오류를 반지하는 collections.defaultdict(), 요소의 값을 키로 하고 개수를 값 형태로 만들어 카운팅하는 collections.Counter()등이 있다.
defaultdict 객체
존재하지 않는 키를 조회할 경우, 에러 메시지를 출력하는 대신 디폴트 값을 기준으로 해당 키에 대한 딕셔너리 아이템을 생성해준다.
a = collections.defaultdict(int)
a['A'] = 5
a['B'] = 4
print(a)
# {'A': 5, 'B': 4}
a['C'] += 1
print(a)
# {'A': 5, 'B': 4, 'C': 1}
존재하지 않는 키C는 defaultdict에 의해 디폴트값인 0을 기준으로 자동 생성 후 +1연산을 통해 1이 만들어짐을 확인할 수 있다.
Counter 객체
아이템에 대한 개수를 계산해 딕셔너리로 리턴한다.
a = [1, 2, 3, 4, 5, 5, 5, 6, 6]
b = collections.Counter(a)
print(b)
# Counter({5: 3, 6: 2, 1: 1, 2: 1, 3: 1, 4: 1})
- Counter객체를 사용해 가장 빈도수가 높은 요소 추출 (most_common()사용)
b.most_common(2)
# [(5,3), (6,2)]
OrderedDict 객체
입력 그대로 순서가 유지된다. (python 3.6이하)
collections.OrderedDict({('banana', 3), ('apple', 4), ('pear', 1), ('orange', 2)})
# OrderedDict([('banana', 3), ('apple', 4), ('pear', 1), ('orange', 2)])
인텐트(Intent)
파이썬의 대표적인 특징인 인텐트(Intent)는 공식 가이드인 PEP 8에 따라 공백 4칸을 원칙으로 한다.
추가로, 아래의 코드와 주석과 같은 기준들이 포함되어있다.
# 첫 번째 줄에 파라미터가 있다면, 파이미터가 시작되는 부분에 맞춘다.
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 첫 번째 줄에 파라미터가 없다면, 공백 4칸(인텐트)를 추가하여 다른 행과 구분한다.
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# 여러 줄로 나눠쓸 경우 다음 행과 구분되도록 인텐트를 추가한다.
foo = long_function_name(
var_one, var_two,
var_three, var_four)
네이밍 컨벤션(Naming Convention)
파이썬의 변수명은 각 단어를 밑줄(_)로 구분하여 표기하는 스네이크 케이스(Snake Case)를 따른다.
타입 힌트(Type Hint)
파이썬에서도 타입 힌트(Type Hine)를 사용해 변수에 타입을 지정할 수 있다.
코드를 통해 타입 힌트를 사용할 때와 사용하지 않을때를 비교해본다.
- Type Hint를 사용하지 않은 경우
def fn(a):
...
빠르게 정의해서 사용할 수 있는 것이 장점이지만, 파라미터 a에 정수를 넣어야하는지 문자를 넣어야하는지 알 수가 없다. 프로젝트의 규모가 커지면서 가독성을 떨어트려 버그 유발에 주범이 된다.
- Type Hint를 사용한 경우
def fn(a: int) -> bool:
...
타입 힌트를 사용하면 파라미터 a에는 정수를 넣어햐함을 확실히 알 수 있으며, 리턴값으로 True or False를 리턴할 것이라는 점도 알 수 있다.
타입 힌트에 오류를 파악하고 싶다면 mypy를 사용하면 된다.
$ pip install mypy # mypy 설치
$ mypy solution.py # mypy 사용
리스트 컴프리헨션(List Comprehension)
리스트 컴프리헨션이란?
- 기존 리스트를 기반으로 새로운 리스트를 만들어내는 구문이다.
다방면에 유용하게 사용되며 람다(lambda)에 map, filter를 사용하는 것보다 가독성이 뛰어나다.
아래의 예시 코드는 홀수 인 경우 2를 곱해 출력하는 코드이다.
# List Comprehension을 사용한 경우
[n*2 for n in range(1, 10+1) if n % 2 == 1 ]
# List Comprehension을 사용하지 않은 경우
a = []
for n in range(1, 10+1):
if n % 2 == 1:
a.append(n*2)
버전 2.7 이후에는 딕셔너리도 가능하다.
# Dictionary Comprehension을 사용한 경우
a = {key: value for key, value in original.items()}
# Dictionary Comprehension을 사용하지 않은 경우
a = {}
for key, value in original.items():
a[key] = value
제너레이터(Generator)
제너레이터란?
- 루프의 반복 동작을 제어할 수 있는 루틴 형태를 의미한다.
예를 들어, 임의의 조건으로 숫자 1억개를 만들어내 계산하는 프로그램인 경우, 제너레이터가 없다면 메모리 어딘가에 만들어낸 숫자 1억개를 보관하고 있어야한다. 하지만 제너레이터를 사용하면 필요할 때 언제든 숫자를 만들어낼 수 있다.
yield구문을 사용하면 제너레이터를 리턴할 수 있다. yield는 제너레이터가 여기까지 실행 중이던 값을 내보낸다는 의미로, 리턴한 다음 함수는 종료되지 않고 계속해서 맨 끝에 도달할 때까지 실행된다.
def get_natural_number():
n = 0
while True:
n += 1
yield n
# 함수의 리턴값은 제너레이터가 된다.
>>> get_natural_number()
<generator object get_natural_number at 0x00000163602E09C8>
만약 다음 값을 생성하려면 next()로 추출하면 된다. ex) 100개의 값을 생성하고 싶다면 아래의 코드처럼 사용하면 된다.
g = get_natural_number()
for _ in range(0, 100):
print(next(g))
또한, 제너레이터는 여러 타입의 값을 하나의 함수에서 생성하는 것도 가능하다.
def generator():
yield 1
yield 'String'
yield True
g = generator()
g_value = next(g)
print('값 : {}, 타입 : {}'.format(g_value,type(g_value)))
# 값 : 1, 타입 : <class 'int'>
g_value = next(g)
print('값 : {}, 타입 : {}'.format(g_value,type(g_value)))
# 값 : String, 타입 : <class 'str'>
g_value = next(g)
print('값 : {}, 타입 : {}'.format(g_value,type(g_value)))
# 값 : True, 타입 : <class 'bool'>
range
제너레이터의 방식을 활용하는 대표적인 함수는 range()이다.
아래의 코드와 같이 사용된다.
list(range(5))
# [0, 1, 2, 3, 4]
range(5)
# range(0, 5)
type(range(5))
# <class 'range'>
for i in range(5):
print(i, end='')
# 0 1 2 3 4
range()는 range 클래스를 리턴하며, for 문에서 사용할 경우 내부적으로는 제너레이터의 next()를 호출하듯 매번 다음 숫자를 생성해낸다.
다음은 숫자 100만개를 생성하는 2가지 방법이다.
a = [n for n in range(1000000)]
b = range(1000000)
둘의 길이를 비교해보면 동일하게 100만개가 출력된다.
하지만 a에는 이미 생성된 값이 담겨 있고, b는 생성해야 한다는 조건만 존재한다.
a와 b의 메모리 점유율을 비교해보자
sys.getsizeof(a)
# 8697464
sys.getsizeof(b)
#48
b는 생성 조건만 보관하고 있기 때문에 a에 비해 메모리 점유율이 현저히 적다. 또한, b는 인덱스 접근이 바로 가능해 리스트와같이 사용할 수 있다.
enumerate
enumerate란?
- 순서가 있는 자료형(list, set, tuple 등)을 인덱스를 포함한 enumerate객체로 리턴한다.
a = [1, 2, 3, 2, 45, 2, 5]
enumerate(a)
# <enumerate at 0x16363b81818>
list(enumerate(a))
# [(0, 1), (1, 2), (2, 3), (3, 2), (4, 45), (5, 2), (6, 5)]
a = [‘a1’, ‘b1’, ‘c1’]의 경우에는 어떻게 리스트의 인덱스와 값을 한번에 출력할까?
a = ['a1', 'b1', 'c1']
for idx, val in enumerate(a):
print(idx, val)
// 나눗셈 연산자
// 연산자란?
- 몫을 구하는 연산자이다.
% 연산자란?
- 나머지를 구하는 연산자이다.
5/3
# 1.6666666666666667
5//3
# 1
5%3
# 2
몫과 나머지를 동시에 구하려면 어떻게 해야할까?
divmod()함수를 사용하면 된다.
divmod(5, 3)
# (1, 2)
가장 쉽게 값을 출력하는 방법은 콤마(,)로 구분하는 것이다. 띄어쓰기를 사용해 값을 구분해준다.
print('A1', 'B2')
# A1 B2
sep 파라미터를 사용해 구분자를 다른 문자,기호로 바꿀 수 있다.
print('A1', 'B2', sep='/')
# A1/B2
print()는 항상 줄바꿈을 하기 때문에 긴 루프의 값을 반복적으로 출력하면 디버깅이 어렵다. 이때, end 파라미터를 사용해 줄바꿈을 하지 않도록 제한할 수 있다.
print('aa', end=' ')
print('bb')
# aa bb
리스트를 출력할 때는 join()으로 묶어서 처리한다.
a = ['A', 'B']
print(' '.join(a))
# A B
format을 사용해 원하는 데이터를 위치에 맞게 출력할 수 있다.
idx = 1
fruit = 'Apple'
print('{0} : {1}'.format(idx+1, fruit)) # 인덱스를 부여해 사용 가능하다.
# 2 : Apple
print('{1} : {0}'.format(idx+1, fruit)) # 인덱스의 순서를 변환해 사용 가능하다.
# Apple : 2
print('{} : {}'.format(idx+1, fruit)) # 인덱스를 생략할 수 있다.
# 2 : Apple
f-string방법을 사용해 출력이 가능하다. .format을 부여하는 방식에 비해 훨씬 간결하고 직관적이며 속도도 빠르다. (파이썬 3.6+에서만 지원)
print(f'{idx+1}: {fruit}')
# 2: Apple
pass
pass의 기능은?
- 널 연산으로 아무것도 하지 않는 기능이다.
pass를 사용해 목업 인터페이스를 구현할 때 편리하다.
locals
locals()란?
- 로컬 심볼 테이블 딕셔너리를 가져오는 메소드이다.
로컬에 선언된 모든 변수를 조회할 수 있는 강력한 명령이므로 디버깅에 많은 도움이 된다.
클래스의 특정 메소드 내부에서나 함수 내부의 로컬 정보를 조회해 잘못 선언한 부분이 없는지 확인하는 용도로 활용이 가능하다.
import pprint
pprint.pprint(locals())
# {'nums': [2, 7, 11, 15],
# 'pprint': <module 'pprint' from '/usr/lib/python3.8/pprint.py'>,
# 'self': <__main__.Solution object at 0x7f0994769d90>,
# 'target': 9}
# 클래스 메소드 내부의 모든 로컬 변수를 출력해 주기 때문에 디버깅에 많은 도움이 된다.