파이썬 알고리즘 인터뷰_문자열 조작
«파이썬 알고리즘 인터뷰 서적 내용을 정리»
문제01 유효한 팰린드롬
https://leetcode.com/problems/valid-palindrome/
주어진 문자열이 팰린드롬인지 확인해라. 대소문자를 구분하지 않으며, 영문자와 숫자만을 대상으로 한다.
Example 1:
Input: "A man, a plan, a canal: Panama" Output: trueExample 2:
Input: "race a car" Output: false
- 내 코드
class Solution:
def isPalindrome(self, s: str) -> bool:
# lower()함수로 소문자로 변경 후, 정규표현식을 사용해 영어와 숫자만 대상으로 한다.
text = list(re.sub('[^a-z0-9]','',s.lower()))
# 맨 앞의 문자와 맨 뒤의 문자를 추출해 비교한다.
while len(text) > 1:
if text.pop() != text.pop(0):
return False
return True
isPalindrome("A man, a plan, a canal: Panama")
Result
Runtime : 232ms, Memory : 15.9MB
- 풀이1_리스트로 변환
class Solution:
def isPalindrome(self, s: str) -> bool:
# isalnum()을 사용해 영문자와 숫자를 판별후 소문자로 변환한다.
strs = []
for char in s:
if char.isalnum():
strs.append(char.lower())
# 맨 앞의 문자와 맨 뒤의 문자를 추출해 비교한다.
while len(strs) > 1:
if strs.pop() != strs.pop(0):
return False
return True
isPalindrome("A man, a plan, a canal: Panama")
- isalnum() : 문자열이 영어, 한글 혹은 숫자로 되어있으면 참 리턴, 아니면 거짓 리턴
Result
Runtime : 292ms, Memory : 20.1MB
- 풀이2_데크 자료형을 이용한 최적화
class Solution:
def isPalindrome(self, s: str) -> bool:
# 자료형 데크로 선언
strs : Deque = collections.deque()
# isalnum()을 사용해 영문자와 숫자를 판별후 소문자로 변환한다.
for char in s:
if char.isalnum():
strs.append(char.lower())
# 맨 앞의 문자와 맨 뒤의 문자를 추출해 비교한다.
while len(strs) > 1:
if strs.popleft() != strs.pop():
return False
return True
isPalindrome("A man, a plan, a canal: Panama")
Result
Runtime : 68ms, Memory : 19.4MB
-
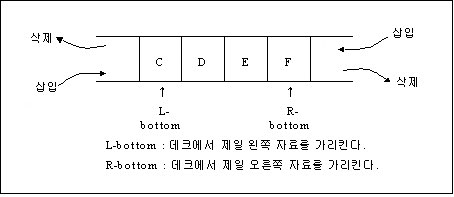
데크(Deque)란?
양방향에서 삽입과 삭제가 일어나는 구조
list가 아닌 deque를 사용하는 이유?
- 시간 복잡도 때문에! (참고 : https://wiki.python.org/moin/TimeComplexity)
- 풀이3_슬라이싱 사용
class Solution:
def isPalindrome(self, s: str) -> bool:
# 소문자 변환
s = s.lower()
# 정규식으로 불필요한 문자 필터링
s = re.sub('[^a-z0-9]', '', s)
# 슬라이싱
return s == s[::-1]
isPalindrome("A man, a plan, a canal: Panama")
Result
Runtime : 36ms, Memory : 15.6MB
문자열 슬라이싱
 ↑슬라이싱에 사용할 예시 문장 및 인덱스
↑슬라이싱에 사용할 예시 문장 및 인덱스
| 슬라이싱 방법 | 결과 | 설명 |
|---|---|---|
| s[1:4] | 녕하세 | 인덱스 1에서 4이전까지 표현 |
| s[1:-2] | 녕하 | 인덱스 1에서 -2이전까지 표현 |
| s[1:] | 녕하세요 | 문자열 시작 또는 끝은 생략 가능 |
| s[:] | 안녕하세요 | 둘다 생략하면 사본을 리턴한다. |
| s[1:100] | 녕하세요 | 인덱스가 지나치게 클 경우 문자열의 최대 길이만큼만 표현, S[1:]와 동일하다. |
| s[-1] | 요 | 마지막 문자(뒤에서 첫 번째) |
| s[-4] | 녕 | 뒤에서 4번째 |
| s[:-3] | 안녕 | 뒤에서 3번째 문자 앞까지 |
| s[-3:] | 하세요 | 뒤에서 3번째 문자부터 끝까지 |
| s[::1] | 안녕하세요 | 1은 기본값으로 동일하다. |
| s[::-1] | 요세하녕안 | 문자열을 뒤집는다. |
| s[::2] | 안하요 | 2칸씩 앞으로 이동한다. |
| s[::-3] | 요녕 | 뒤에서부터 3칸씩 이동한다. |
문제02 문자열 뒤집기
https://leetcode.com/problems/reverse-string
문자열을 뒤집는 함수를 작성하라. 입력값은 문자 배열이며, 리턴 없이 리스트 내부를 직접 조작하라.
Example 1:
Input: ["h","e","l","l","o"] Output: ["o","l","l","e","h"]Example 2:
Input: ["H","a","n","n","a","h"] Output: ["h","a","n","n","a","H"]
- 내 코드 & 풀이2_파이썬다운 방식
class Solution:
def reverseString(self, s: List[str]) -> None:
s.reverse()
Result
Runtime : 180ms, Memory : 18.4MB
- reverse()함수는 리스트에서만 사용 가능
- 여기서 s[::-1]이 적용 안되는 이유! -> 공간 복잡도를 O(1)로 보고 있기 때문
- 사실은 s[:] = s[::-1]이런 트릭을 사용하면 된다.
- 하지만 위와 같은 트릭을 알아내기 어렵다!
- 풀이1_투 포인터를 이용한 스왑(전통적인 방식)
class Solution:
def reverseString(self, s: List[str]) -> None:
left, right = 0, len(s) -1
while left < right :
s[left], s[right] = s[right], s[left]
left += 1
right -= 1
Result
Runtime : 196ms, Memory : 18.6MB
문제03 로그파일 재정렬
https://leetcode.com/problems/reorder-data-in-log-files
로그를 재정렬하라. 기준은 다음과 같다.
- 로그의 가장 앞 부분은 식별자다.
- 문자로 구성된 로그가 숫자 로그보다 앞에 온다.
- 식별자는 순서에 영향을 끼치지 않지만, 문자가 동일할 경우 식별자 순으로 한다.
- 숫자 로그는 입력 순서대로 한다.
Example 1:
Input: logs = ["dig1 8 1 5 1","let1 art can","dig2 3 6","let2 own kit dig","let3 art zero"] Output: ["let1 art can","let3 art zero","let2 own kit dig","dig1 8 1 5 1","dig2 3 6"]
- 풀이1_람다와 +연산자를 이용
class Solution:
def reorderLogFiles(self, logs: List[str]) -> List[str]:
letters, digits = [], []
for log in logs:
if log.split()[1].isdigit():
digits.append(log)
else:
letters.append(log)
letters.sort(key = lambda x : (x.split()[1:], x.split()[0]))
return letters+digits
Result
Runtime : 36ms, Memory : 14.3MB
- isdigit() 함수를 사용해 숫자 판별 (추가 설명 : )
- lambda 표현식을 이용해 정렬 (추가 설명: )
- ’’+’’ 연산자를 사용해 리스트 이어 붙이기
문제04 가장 흔한 단어
https://leetcode.com/problems/most-common-word
금지된 단어를 제외한 가장 흔하게 등장하는 단어를 출력하라. 대소문자 구분을 하지 않으며, 구두점(마침표, 쉼표 등) 또한 무시한다.
Example 1:
Input: paragraph = "Bob hit a ball, the hit BALL flew far after it was hit." banned = ["hit"] Output: "ball"
- 내 코드
class Solution:
def mostCommonWord(self, paragraph: str, banned: List[str]) -> str:
paragraph = re.sub("[^a-z0-9]", ' ', paragraph.lower()).split()
paragraph_without_banned = [p for p in paragraph if p not in banned]
cnt = collections.Counter(paragraph_without_banned)
return cnt.most_common(1)[0][0]
Result
Runtime : 40ms, Memory : 14.5MB
- 풀이1_리스트 컴프리헨션, Counter 객체 사용
class Solution:
def mostCommonWord(self, paragraph: str, banned: List[str]) -> str:
words = [word for word in re.sub("[^\w]", " ", paragraph).lower().split() if word not in banned]
counts = collections.Counter(words)
return counts.most_common(1)[0][0]
Result
Runtime : 32ms, Memory : 14.4MB
문제05 그룹 애너그램
https://leetcode.com/problems/group-anagrams
문자열 배열을 받아 애너그램 단위로 그룹핑하라.
Example 1:
Input: strs = ["eat","tea","tan","ate","nat","bat"] Output: [["bat"],["nat","tan"],["ate","eat","tea"]]Example 2:
Input: strs = [""] Output: [[""]]Example 3:
Input: strs = ["a"] Output: [["a"]]
- 풀이1_정렬하여 딕셔너리에 추가
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
anagrams = collections.defaultdict(list)
for word in strs:
# 정렬하여 딕셔너리 추가
anagrams[''.join(sorted(word))].append(word)
return list(anagrams.values())
Result
Runtime : 92ms, Memory : 17.2MB
문제06 가장 긴 팰린드롬 부분 문자열
https://leetcode.com/problems/longest-palindromic-substring
가장 긴 팰린드롬 부분 문자열을 출력하라.
Example 1:
Input: s = "babad" Output: "bab" Note: "aba" is also a valid answer.Example 2:
Input: s = "cbbd" Output: "bb"Example 3:
Input: s = "a" Output: "a"Example 4:
Input: s = "ac" Output: "a"
- 풀이1_중앙을 중심으로 확장하는 풀이
class Solution:
def longestPalindrome(self, s: str) -> str:
# 팰린드롬 판별 및 투 포인터 확장
def expand(left: int, right: int) -> str:
while left >= 0 and right < len(s) and s[left] == s[right]:
left -= 1
right += 1
return s[left + 1:right]
# 해당 사항이 없을 때 빠르게 리턴
if len(s)<2 or s == s[::-1]:
return s
result = ''
# 슬라이딩 윈도우 우측으로 이동
for i in range(len(s) - 1):
# 짝수는 2->4->6으로 확장, 홀수는 3-> 5->7로 확장
result = max(result, expand(i, i+1), expand(i, i+2), key=len)
return result
Result
Runtime : 248ms, Memory : 14.5MB
